激活函数给神经网络引入了非线性因素,大大增加了神经网络的可解释性难度。常用激活函数大致经历了sigmoid到tanh到ReLU的演变过程。
sigmoid
公式
$$\sigma (x) = \frac{1}{1+e^{-x}}$$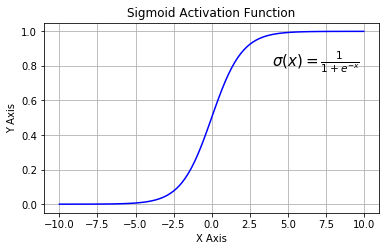
性质
函数饱和导致梯度消失问题,当神经元的激活值在0和1附近时,梯度接近为0,会饱和,导致梯度消失,几乎没有信号通过神经网络传回上一层。
函数输出不是以0为中心,导致梯度下降权重更新时出现z字型下降。
tanh
双曲正切函数
公式
$$\sigma (x) = \frac{e^x - e^{-x}}{e^x+e^{-x}}$$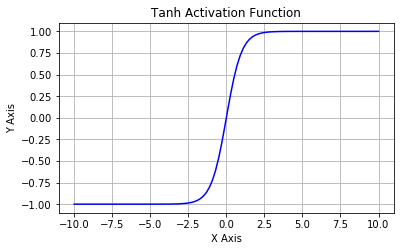
性质
解决了sigmoid函数输出不以0为中心的问题,仍然存在饱和问题。
ReLU
Rectified Linear Unit(ReLU),目前最常用的激活函数。
公式
$$\sigma (x) = max(x, 0)$$
当输入x>0时,输出为x,当输入x<0时,输出为0。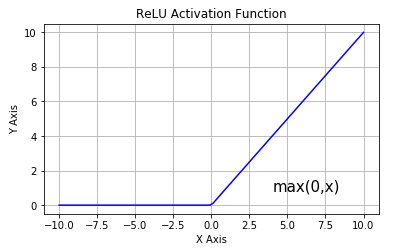
性质
计算简单,效率高,不会饱和,对随机梯度下降的收敛有巨大的加速作用。由于其稀疏激活性,ReLU神经元很容易die并且不可逆,导致数据多样化的丢失,模型无法学习到有效特征。
Leaky ReLU
公式
$$\sigma (x) = max(\varepsilon x, x)$$
$\varepsilon$是一个比较小的负数梯度值,例如0.01。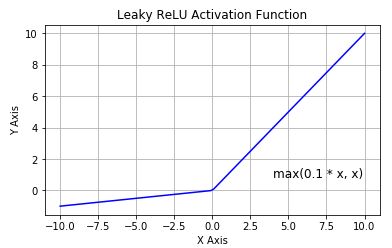
性质
使负轴信息不会全部丢失,解决了ReLU中神经元die掉的问题。
softmax
将神经网络的输出转换为可能性大小,用在最后一层输出层,输出值在[0,1]范围内,同时各输出值相加和为1,满足输出值代表的可能性的概率分布。
公式
$${\sigma (\mathbf{z})}_{j} = \frac{e^{z_j}}{\sum_{k=1}^{K}{e^{z_k}}},\mathrm{for}j=1,…,K$$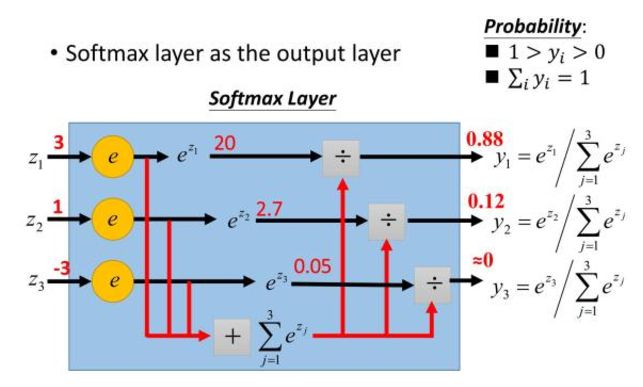
Reference
https://zhuanlan.zhihu.com/p/32610035
https://feisky.xyz/machine-learning/neural-networks/active.html
https://www.jiqizhixin.com/articles/2017-11-02-26
https://zh.wikipedia.org/wiki/%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0
https://www.jianshu.com/p/22d9720dbf1a